The explicit study of causality in AI fields has officially hit the ‘hype cycle’, at least according to Gartner [1]. There are usually important reasons...
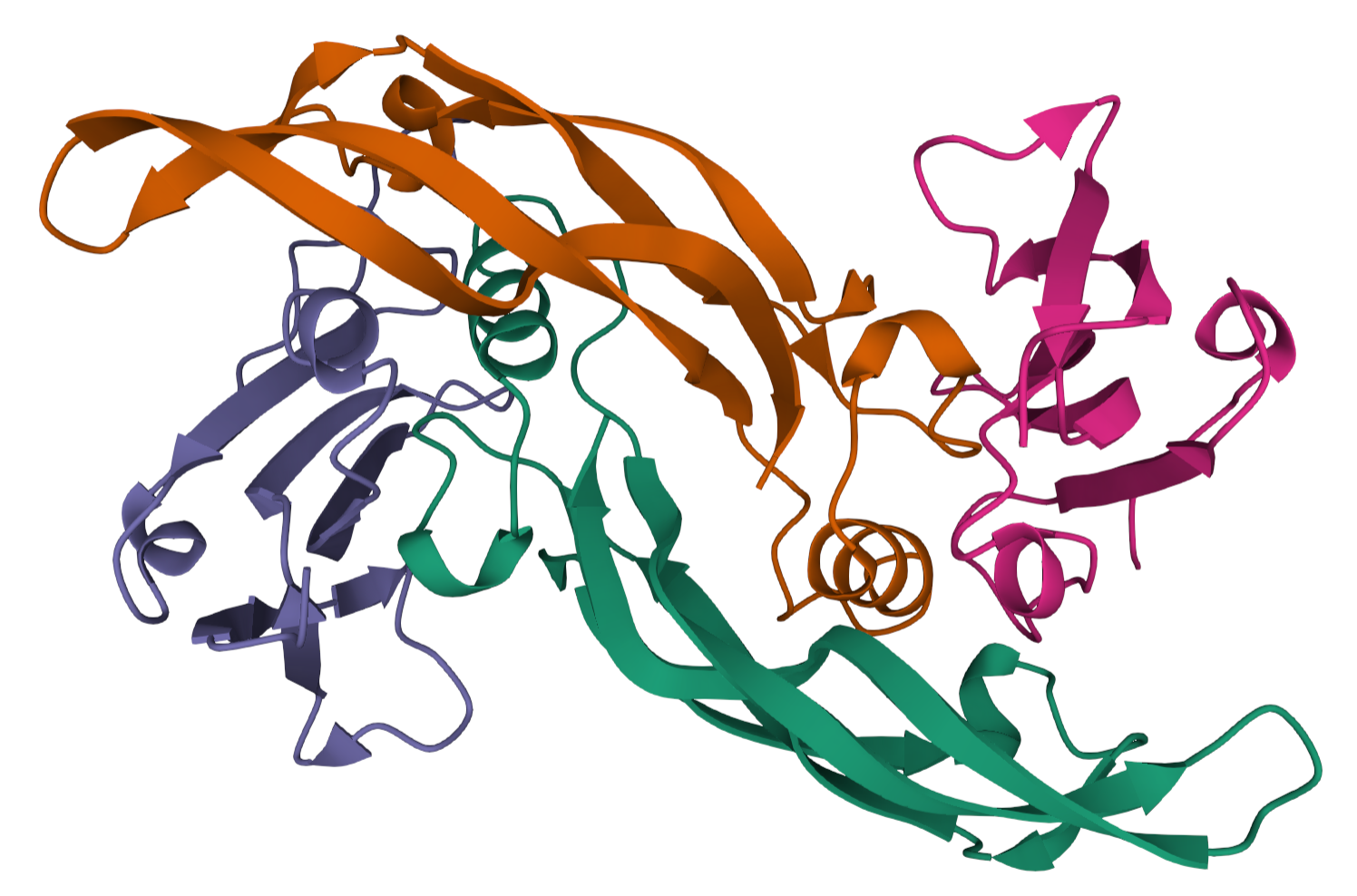
One of the most exciting applications of advancements in artificial intelligence has been the modelling of protein structures and protein folding. Last year DeepMind announced...
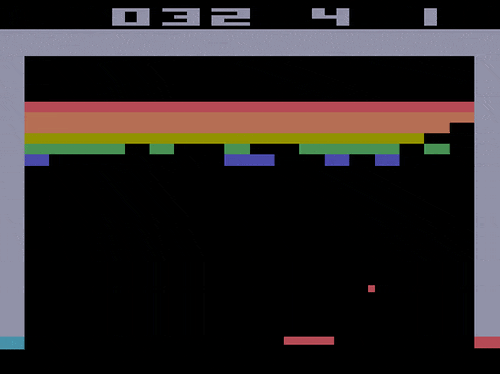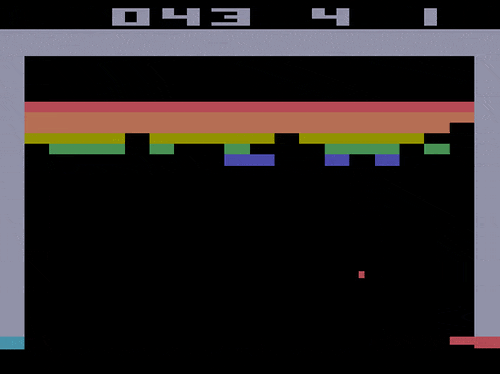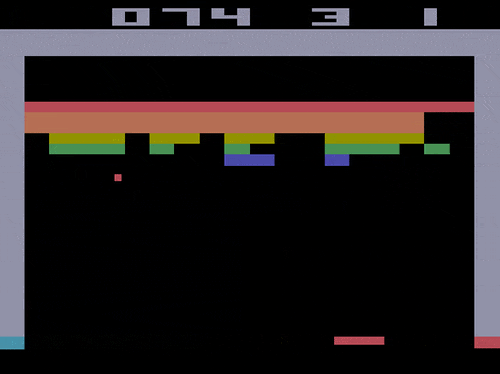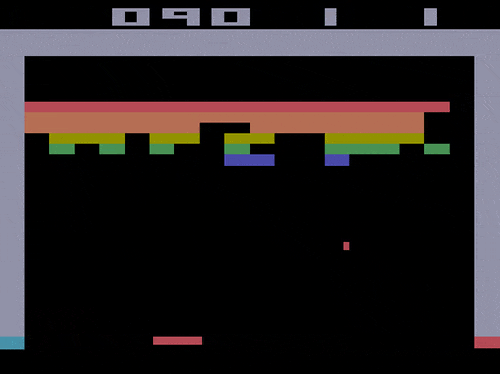
Model-free reinforcement learning algorithms are a class of algorithms which do not use the transition probability information to train and make decisions. In a sense,...
The explicit study of causality in AI fields has officially hit the ‘hype cycle’, at least according to Gartner [1]. There are usually important reasons these fields of study gain...
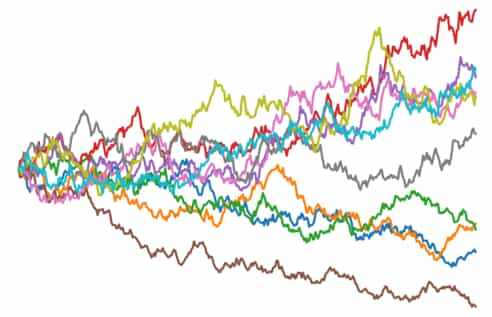
Ah banking, exciting stuff, right? I’ve recently found some enjoyment in simulating fee profiles, rewards, and payoffs of different strategies associated with banking and credit facilities. This is a simple...
One of the most exciting applications of advancements in artificial intelligence has been the modelling of protein structures and protein folding. Last year DeepMind announced their AlphaFold project, which claims...
As a student - or any busy professional - can attest, keeping track of tasks can be a nightmare. Besides simply tracking when tasks are due, it is often helpful...
Introduction Fokker-Planck equations, and stochastic differential equations in general, have many powerful applications in a wide ranging set of fields. These include modelling of Brownian motion in physical systems, electronic...
And as quickly as that, we’re at task 6 of our quest. Causal imitation learning is perhaps the most fanciful-sounding, but at it’s core it remains as simple a goal...
We’ve now come to one of the most vital aspects of this theory - how can we learn causal models? Learning models is often an exceptionally computationally intensive process, so...
At this point we’ve developed a good sense of the technical theory of causal reinforcement learning. This next section brings together many important ideas and generalises notions of data transfer...
In the previous blog post we discussed some theory of how to select optimal and possibly optimal interventions in a causal framework. For those interested in the decision science, this...