
At this point we’ve developed a good sense of the technical theory of causal reinforcement learning. This next section brings together many important ideas and generalises notions of data transfer between different environments. This will prove important when we discuss imitation learning in the future. For those coming from a more pure reinforcement learning background, being able to generalise results about where and when we can transfer knowledge between related domains is clearly useful for a general agent. Let’s get going!
Generalisability and Robustness
One of the most important features of human intelligence is its ability to generalise and transfer causal knowledge across seemingly disparate domains. This allows powerful inferences and decision making procedures possible even in foreign environments. Bareinboim and Pearl address the problem of transferring knowledge from data collected in heterogeneous domains to some target domain - a problem known as -transportability. In 1Bareinboim, E., & Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. NIPS. the authors establish a necessary and sufficient condition for deciding whether this transfer is feasible. In the sciences, powerful studies involving transfer of knowledge across related domains are known as meta-analysis or externally valid studies. The transfer of causal knowledge is known as transportability and is a crucial ability needed for artificial agents to automate the process of knowledge acquisition, discovery and learning.
Consider an example in which we would like to use knowledge of social science experiments done in Los Angeles (predicting outcome with cause , confounded by some age distribution ) to make similar predictions in New York. Calling the distribution in Los Angeles , we would like to predict - the cause/effect relationship under a different age distribution in New York. We call the process which generates this difference in age across the populations a difference generating factor, denoted graphically by , which are caused by some set of selection variables . In this case we have . We can then derive an remarkably simple transport formula as follows:
This deceptively simple formula tells us we can estimate - an interventional quantity - using a drop in observational distribution . This acts to re-weight observations by the interventional affect in a different domain. To generalise a transport formula is not completely trivial. We need to know whether -calculus is complete. That is, whether -calculus operations can always find such a transport formula. Recall that causal models and induced diagrams encode relationships under a particular domain. A formalism that is helpful for the study of transfer of knowledge across causal domains is the notion of selection diagrams. These diagrams graphically encode the shared causal relations and difference generating factors of different causal systems.
Selection Diagrams 1Bareinboim, E., & Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. NIPS.: Let be a pair of structural causal models from domains , sharing causal diagram . The pair induces a selection diagram if obeys the following criteria: (1) every edge in G is also an edge in D, and (2) D contains an extra edge whenever there might exist some discrepancy or between and .
These variables in the selection diagram serve as identifying the mechanisms where structural differences in the data generating process takes place between models under different domains. Knowledge of these structural overlaps of different causal domains allows us to formalise what it means to transfer knowledge between domains. This is the notion of -transportability discussed earlier. Simply put, knowledge is transferable between domains only if the causal effect can be determined from information available in the observational and interventional distributions.
-Transportability 1Bareinboim, E., & Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. NIPS.: Let be a collection of selection diagrams with source domains and target domain . Let be the variables in which experiments can be conducted in domain . If are the observational and interventional distributions, then the causal effect is said to be -transportable from to in if is uniquely computable from in any model that induces .
The above graphical condition has a counterpart that can be written in terms of -calculus criteria.
Theorem: Let symbols be defined as above. The effect is -transportable from to if the expression is reducible using the rules of -calculus to an expression in which (1) do-operators that apply to subsets o have no -variables or (2) do-operators apply only to subsets of .
This theorem tells us that do-calculus is complete in terms of finding these transport formulae. The authors also prove completeness for an established algorithm for computing transport formulae. Refer to source material 1Bareinboim, E., & Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. NIPS. for details of this algorithm.

Figures (a) through (f) show illustrative examples of transportability in causal selection diagrams. These highlight the important of the nature of unobserved confounders. (a) This diagram shows an example of when transportability of is trivially solved by re-weighting of the variable directly affected by difference-generating variable. In this case . (b) shows the simplest example in which one cannot transport a causal relation between domains. Even by randomisation on , the causal effect is not uniquely computable due to UCs. (c) and (d) show examples where transportability of causal effects require interventional information over in and in , but not over in the combined domain. (e) and (f) show examples where transportability is only possible in the combined domain. Figure extracted from 1Bareinboim, E., & Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. NIPS..
This process of transferring knowledge relates well to the concept of unifying big data. The ability to fuse multiple datasets, collected under heterogeneous conditions, without incurring large bias penalties is something critically important for generalising an agent’s ability to learn under different conditions. In 2Bareinboim, E., & Pearl, J. (2016). Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences 113:7345–7352. Bareinboim and Pearl review this problem of data fusion under the auspice of causal inference. In 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI. Lee et al. argue that identifiability and randomisation are two extremes in approach to inferring cause-effect relationships from some combination of observations, experiments and prior (substantive) knowledge. In fact, - identifiability (zID) generalises exactly this question for the case where all possible interventions (experiments) are possible. The authors argue that this requirement is (obviously) not always reasonable and propose a generalisation such that any expression derivable from an arbitrary collection of observations and experiments is returned by the proposed algorithm. The following theory is developed to introduce a strategy that is used to prove non-gID (defined later) which allows for a graphical, necessary and sufficient condition for the causal decision problem of interest. We start by defining a c-component.
C-component 4Tian, J., & Pearl, J. (2002). Studies in causal reasoning and learning.: Let causal graph be such that a subset of its bidirected arcs forms a spanning-tree over all its vertices, then is a confounded-component (c-component).
With this definition in mind, notice the c-components in the figure above. We use to denote the set of c-components that partitions the vertices in such that implies that is a c-component for every , the endogenous (visible) variables.
C-forest 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.: A causal graph with root set is an -rooted c-forest if is a c-component with minimal number of edges.
We now refer to the figure below. All of figure (a) through (b) are c-components since there are unobserved confounders (bidirected edges) spanning the vertices. Further \ref{fig
}(a) through \ref{fig}(c) are c-forests since they have minimal number of spanning bidrected edges.Hedge 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.: A hedge is a pair of -rooted c-forests such that
By this definition, figure (a) and (b) are hedges because we can find two c-forests and such that Crucially, (c) is not a hedge since the spanning bidirected edges are not minimal. This type of structure prevents g-identifiability, which is now formalised and discussed.
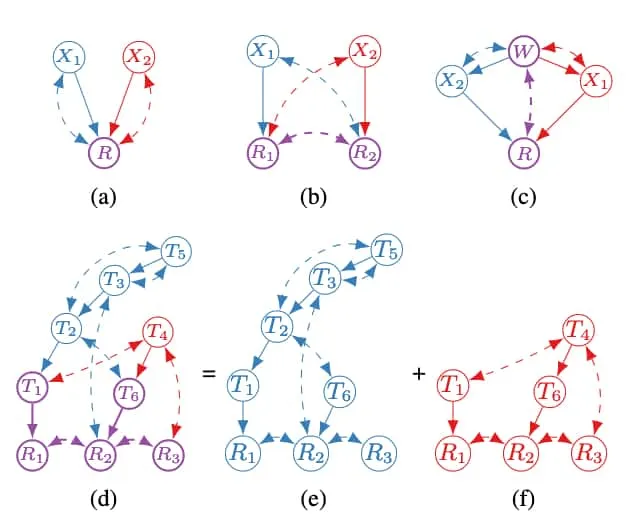
Figure showing examples of hedges, c-components, c-forests, and thickets. These form graphical criteria for g-identifiability. Details are discussed in the text itself. Thickets are shown to preclude g-identifiability. Crucially, (d) is shown to be an overlap of hedges which forms a thicket. Figure extracted from 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI..
g-Identifiability 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.: Let be disjoint sets of variables, be a collection of sets of variables, and let be a causal diagram. If is uniquely computable from distributions in any causal model which induces , we say that is -identifiable from in . Here is the probability distribution describing the natural state of the system (assumed to be available).
Simply put, we say the distribution is -identifiable with respect to a set of intervenable variables in the causal system if they are sufficient to uniquely compute it. This set of variables are the ones we intervene on by doing an experiment, as we discussed earlier. In this way it is a generalisation of -identifiability discussed earlier. We now introduce some more definitions needed for the non-gID criteria.
Hedgelet decomposition 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.: The hedgelet decomposition of a hedge is the collection of hedgelets () where each hedgelet is a subgraph of made of (i) and (ii) without bidirected edges.
Referring back to the reference figure, some possible hedgelet decompositions are colour coded in blue and red to indicate distinct hedgelets, with purple used to indicate the shared variables (commonly root sets). This leads us nicely to the last definition we need for this criterion. Though this definition appears arbitrarily technical, it is rather intuitive once the reasoning is developed.
Thicket 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.: Let be non-empty set of variables and be a collection of sets of variables in . A thicket is an -rooted c-component consisting of a minimal c-component over and hedges
Let’s consider this definition step-by-step by considering figure (c). First, we notice the graph is a c-component that contains a minimal c-component. It does not necessarily need to be a c-forest itself. Next, we need a pair of -rooted c-forests . We select the graphs induced by sets and with the intervention set. Then we have hedges and that overlap and have intervention variables that do not intersect with the root set, . Basically, a thicket is an overlapping of hedges, and hedges were the ‘bad’ structure that prevented gID in the causal graph. Though this is a fairly involved procedure to do manually, especially on large causal graphs, it is algorithmically feasible as shown in Lee et al. The usefulness of this algorithm relies on the following result.
Thicket non-gID 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.: If there exists some thicket for in causal graph with respect to intervention set , then is not g-identifiable in .
To make this idea explicit we include the following figure extracted from slides provided directly by Sanghack Lee, coauthor of several papers (including 3Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.) presented in this work 5Lee, S. (2020). General identifiability with arbitrary surrogate experiments. AAAI 2020 (presented at UAI 2019)..
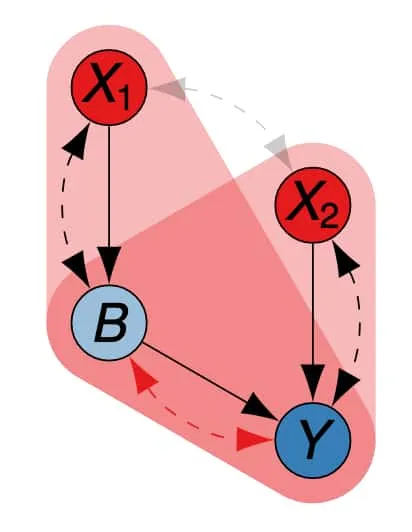
Thicket structure for identified as an overlap of distinct hedges, each colours as a red rounded triangle. Extracted from 5Lee, S. (2020). General identifiability with arbitrary surrogate experiments. AAAI 2020 (presented at UAI 2019)..
This completes the required formalism’s for identifying structural constraints from explicit causal models. This ties well into the next section in which we discuss how we can apply this theory to learn causal structure from observational and interventional data. This is especially useful for allowing reinforcement learning agents to uncover causal structure.
Image credit: Header Image.
{kind=link}
References
- Bareinboim, E., & Pearl, J. (2014). Transportability from multiple environments with limited experiments: Completeness results. NIPS.
- Bareinboim, E., & Pearl, J. (2016). Causal inference and the data-fusion problem. Proceedings of the National Academy of Sciences 113:7345–7352.
- Lee, S., Correa, J. D., & Bareinboim, E. (2019). General identifiability with arbitrary surrogate experiments. UAI.
- Tian, J., & Pearl, J. (2002). Studies in causal reasoning and learning.
- Lee, S. (2020). General identifiability with arbitrary surrogate experiments. AAAI 2020 (presented at UAI 2019).

Comments are being migrated. Check back soon.