
We’ve now come to one of the most vital aspects of this theory - how can we learn causal models? Learning models is often an exceptionally computationally intensive process, so getting this right is crucial. We now develop some mathematical results which guarantee bounds on our learning. We’ll start by discussing the current state of this field in relation to causal inference and reinforcement learning.
Learning Causal Models
Perhaps one of the most computationally difficult processes in the field of causal inference is that of learning underlying causal structure by algorithmically identifying cause-effect relationships. In recent years there has been a surge of interest in learning such relationships in the fields of machine learning and artificial intelligence, though it has been relatively prevalent in the social sciences for many years now (e.g. 1Granger, C. W. J. (1969). Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37:424–438. has over 25000 citations at time of writing). The discovery of IC and PC 2Spirtes, P., Glymour, C., & Scheines, R. (2000). Causation, Prediction, and Search (2nd ed.). Adaptive Computation and Machine Learning. algorithms independently displayed the feasibility of learning such causal structure from observational data - a fact that was not obvious at the time. Since these discoveries new methods of inferring such structure have emerged. Many of these methods require satisfaction of the strict causal sufficiency assumption. This requires that no latent variables affects more than one observed variable. In other words, these algorithms do not deal with confounding.
3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS. improves upon previous work by introducing an algorithm that can learn any causal graph, as well as the existence and location of the latent variables using interventions, where is the largest node degree, and is the longest directed path of the causal graph. Further, they introduce a probabilistic algorithm which can learn the observable graph and all the latent variables using interventions with high probability. We discuss and develop this theory as it is deemed a particularly interesting approach to the problem at hand. The authors split the task of learning the observable graph and latent variables into three distinct sub-tasks. They start by proposing a method for finding the transitive closure of the observable graph. Next, this transitive closure is reduced to reveal some subset of the edges in the underlying causal graph. Conditional independence tests are then used to uncover latent variables. We now discuss select theory in detail.
The authors begin by showing that separating systems can be used to construct sequences of pairwise conditional independence tests to discover the transitive closure of the observable causal graph. That is, to discover the causal paths in the causal system by testing which variables ‘rely’ on other variables (in an informal sense). To develop this idea formally we require the idea of a post-interventional causal graph. This is simply the causal graph with all edges directed onto intervened variables, removed. Recall that faithfulness indicates that causal relations are only formed as a result of d-separation. Simply put, there are no relationships that perfectly balance each other so as to appear to have no causal relations. These conditions allow us to formalise the conditional independence test we require.
Pairwise Conditional Independence Test 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS.: Consider causal graph with latent variables , and an intervention set of observable variables. Applying the post-interventional faithfulness assumption, we have that for any pair if and only if is an ancestor of in the post-interventional graph
This lemma provides a method for determining ancestry for any ordered pair of variables, Crucially though, this method is not sufficient. For example, consider where The authors propose resolving this issue by using a sequence of interventions guided by a separating system. The correct causal graph can then be learned by finding the transitive closure.
Strongly Separating System 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS.: An strongly separating system is a collection of subsets of the ground set such that for any two pairs of nodes and , there exists a set in the family such that and also another set such that .
This definition is useful because, as shown in 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS., a strong separating system always exists on ground set when . This allows us to introduce a deterministic algorithm for learning the observable causal graph from the ancestral relationships, which requires only interventions and conditional independence tests. A key insight for the deterministic algorithm is that whenever the intervention set contains all parents of , the only variables that are dependent with in the post-interventional set are the parents, . Consider , the longest directed path of . Using the obvious partial order on the vertex set , we can define a unique partitioning of vertices where . Each node in is thus a set of of mutually incomparable elements and represents the set of nodes at layer in the transitive closure graph . Define , then - a fact that is exploited for the deterministic algorithm the authors present.
Perhaps the most interesting aspect of this paper is the randomised algorithm the authors propose. The strategy employed here is to repeatedly use the ancestor graph learning algorithm to learn the observable graph. This procedure makes use of transitive reduction.
Transitive Reduction: Given a directed acyclic graph , let its transitive closure be Then is a directed acyclic graph with minimum number of edges such that its transitive closure is identical to .
This transitive reduction is simple and effective. This allows for an iterative procedure for revealing causal relationships. We now elaborate on this procedure in the following lemma, discussed in 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS..
Lemma: Given intervention set of nodes in the observable causal graph , we can notate the post-interventional observable causal graph as . Now, consider a specific observable node , and let be a direct parent of in such that all the direct parents of above in the partial order are in . Formally, . Then will contain the directed edge and it can be computed from .
To solidify the simplicity of the lemma, consider the figure below. Here we show how an intervention changes what the procedure can reveal about the structure of the transitive relationships in the observable causal graph.
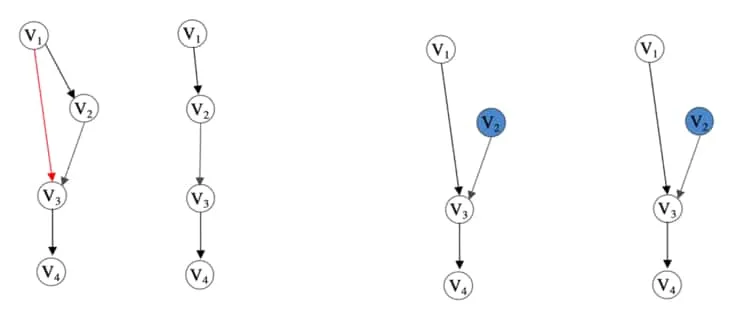
Figure showing examples of theory in 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS.. Starting from the left, we have an example of a graph without latent variables. Next, we have the result of the transitive reduction procedure on the previous graph. Notice that the red edge has not been revealed. Next, we have the same observational graph but with intervened on. This removes the direct causal relation between and and thus reveals edge in the transitive reduction procedure (shown last). Figure extracted from 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS..
This procedure is useful for the probabilistic algorithm the authors propose. Here, the basic idea is that random intervention and transitive closure computation can reveal edges of the underlying causal graph. As we perform more interventions, our certainty about the structure of the observable causal graph rises. The following theorem 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS. formalises this idea.
Theorem: Let exceed the the maximum in-degree in the observable graph . The proposed probabilistic algorithm requires at most interventions and conditional independence tests on samples obtained from post-interventional distributions, and returns the observable portion of the causal graph with a minimum probability of .
We now consider a more involved scenario. Recall that conditioning on an observable is not necessarily sufficient due to backdoor paths. Consider the scenarios in the figure below. On the left, we have an example of a graph where intervening on leaves an influencing path open, . This means that observation does not necessarily match our intervention data, . We must intervene on a parent of to remove confounding influences in this example. Similarly for the graph on the right where we need to intervene on parents of . This motivates the following theorem.
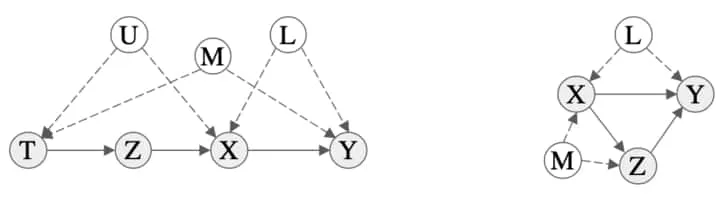
Figure showing examples of graphs that require a more complex intervention to block backdoor paths. Details about these are discussed in the text. Figure extracted from 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS..
Interventional Do-See Test 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS.: Given a causal graph over observable variables and latents . Denoting edge set of by , then
if and only if there exists some such that and . Recall, are the parents of .
The final result of this paper is, perhaps, the most mathematically satisfying and, otherwise, surprising. We will need some theory of graph colourings to present this.
Strong Edge Colouring 3Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS.: A strong edge colouring of a (undirected) graph with colours is a mapping of edges to a colour class, , such that any two distinct edges that are incident on adjacent vertices have different colours assigned to them.
This definition leads to the following result 4Bensmail, J., Bonamy, M., & Hocquard, H. (2015). Strong edge coloring sparse graphs. Electronic Notes in Discrete Mathematics 49:773–778..
Lemma: Given a graph with maximum degree , we can strongly edge colour using at most colours. Simply apply a greedy algorithm to colouring edges in sequence.
Remarkably, only two interventions are required per colour class for the do-see interventional test. That is, one intervention for the ‘do’ part and one for the ‘see’ part. The authors exploit this and the following theorem to present an efficient algorithm for learning the latent edges of an observable graph with maximum degree .
Theorem: At most interventions are required to learn the latent variables in the observable graph.
5Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML. extends the work in causal structure learning by focusing on limiting the interventions to non-adaptive experiments of unit size. The authors show a greedy algorithm achieves a -approximation to the optimal objective. It is well understood that whenever it is possible to perform a sufficient number of interventions, the underlying causal structure of a system can be fully recovered.
The authors propose focusing on the question: “for a fixed budget of interventions, what portion of the causal graph is learnable?” This question is of interest because, in some applications, performing simultaneous interventions on multiple variables is not possible. This relates well to our discussion of and -identifiability. Recall two DAGs are Markov equivalent if they share conditional independence results. This allows the definition of the essential graph, which will prove useful in later results.
Essential Graph 5Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML.: The essential graph of , denoted , is a mixed graph (contains both directed and undirected edges) where the directed edges are the edges that have common direction for all elements in the Markov equivalence class of G. Similarly, the undirected edges are those that differ in direction for at least two elements of the equivalence class.
It is important to clarify what we mean by experiment or intervention. For the most part these are equivalent. In this case, however, we differentiate by noting that an experiment can consist of multiple interventions. Here we wish to deal with one intervention at a time. An interventional structure learning algorithm consists of a set of experiments where each of the experiments contains interventions. The authors consider the situation . The experiment set thus leads to the discovery of the orientation of the edges intersecting members in the set, denoted where represents the true causal DAG. Letting denote the undirected subgraph of (i.e. The subgraph with edges having disagreeing directions in the equivalence class).
Further, letting denote the the subset of that can be learned by applying Meek rules 6Meek, C. (1995). Causal inference and causal explanation with background knowledge. UAI., then represents the cardinality of the set of edges that can be learned by experiment set . Finally, let
Then the problem we are interested in can be formulated as computing
All this formalism says is that we would like maximise the number of edges we can learn about by performing experiments of size one. The problem, however, is that finding such an intervention set, , requires combinatorial search, and computing can be intractable. Dealing with this requires some theory of set functions.
Submodularity 5Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML.: A set function is submodular if for all subsets and all the following condition is satisfied
Given a submodular function with that is monotonically increasing, then the set of interventions found by the greedy algorithm (presented below) satisfies 7Nemhauser, G., Wolsey, L., & Fisher, M. L. (1978). An analysis of approximations for maximizing submodular set functions—I. Mathematical Programming 14:265–294.. Thus, all we need to show is that the set function defined earlier is monotonically increasing and submodular and the result follows. The proof of monotonicity follows fairly easily from the definitions, while the submodularity is more involved. See the supplementary materials in 5Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML. for details.

The greedy algorithm relies on the theory developed and the results presented in the appendices of 5Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML.. This algorithm iteratively adds a variable with the greatest marginal gain to the intervention set, until the budget is exhausted. In other words, it greedily selects a possible intervention. The intractability of computing is addressed by proposing a Monte-Carlo approach. The proposed algorithm employs random sampling and generates multisets of DAGs, , in the algorithm. The following result provides theoretical legitimacy to this method 5Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML..
Theorem: Imagine we are given some estimate of the number of interventions required to learn the about the edges in the underlying causal graph, with . If we are given set and , and if then with probability larger than
Proof: Define for By the assumption of the theorem, Applying the Chernoff bound we have
Therefore,
This further implies
Applying these results, we can set
to obtain an upper bound of . This completes the proof.
The authors further propose accelerating the greedy algorithm by performing \emph{lazy} evaluations. That is, they exploit the monotonicity of the marginal gains such that if and , then . This improves performance in a similar manner to dynamic programming improvements over naive methods. These procedures are combined to empirically show that a significant portion of causal systems can be learned using only a relatively small number of interventions - a remarkable result for a seemingly intractable problem!
The problem of learning causal structure is still a very active area of research. Extension of work presented here is considered in 8Kocaoglu, M., Jaber, A., Shanmugam, K., & Bareinboim, E. (2019). Characterization and learning of causal graphs with latent variables from soft interventions. NeurIPS. and 9Jaber, A., & Kocaoglu, M. (2020). Causal discovery from soft interventions with unknown targets: Characterization and learning. for example. For brevity these are not discussed further. We have developed the bulk of the theory necessary to actually implement some useful and promising agents. The next task develops some theory needed to apply some of these tools to the task of imitation learning.
Image credit: Header Image.
{kind=link}
References
- Granger, C. W. J. (1969). Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37:424–438.
- Spirtes, P., Glymour, C., & Scheines, R. (2000). Causation, Prediction, and Search (2nd ed.). Adaptive Computation and Machine Learning.
- Kocaoglu, M., Shanmugam, K., & Bareinboim, E. (2017). Experimental design for learning causal graphs with latent variables. NIPS.
- Bensmail, J., Bonamy, M., & Hocquard, H. (2015). Strong edge coloring sparse graphs. Electronic Notes in Discrete Mathematics 49:773–778.
- Ghassami, A., Salehkaleybar, S., Kiyavash, N., & Bareinboim, E. (2018). Budgeted experiment design for causal structure learning. ICML.
- Meek, C. (1995). Causal inference and causal explanation with background knowledge. UAI.
- Nemhauser, G., Wolsey, L., & Fisher, M. L. (1978). An analysis of approximations for maximizing submodular set functions—I. Mathematical Programming 14:265–294.
- Kocaoglu, M., Jaber, A., Shanmugam, K., & Bareinboim, E. (2019). Characterization and learning of causal graphs with latent variables from soft interventions. NeurIPS.
- Jaber, A., & Kocaoglu, M. (2020). Causal discovery from soft interventions with unknown targets: Characterization and learning.

Comments are being migrated. Check back soon.