
Where we are
Up to this point we have discussed methods primarily relying on the learning of value functions, usually approximating these with some neural network. That is, our focus has been on trying to learn how much each state is ‘worth’ according to the expected return of being in a specific state. Model-based methods add to this by adding a model of the state dynamics. The aim is to learn how the environment ‘reacts’ to specific actions, giving us the ability to simulate experience and predict the best actions to take from a particular state. The focus here is on state-space planning in which value functions are computed over all possible states. Notice, there are two distinct ideas here:
- Learning a model of the environment (learning); and
- using a model to improve some value function or policy (planning).
Real experience can thus be used in two ways for planning. It can improve the model of the environment and it can be used to directly improve upon a value function or policy. This relationship is encapsulated in the figure below.
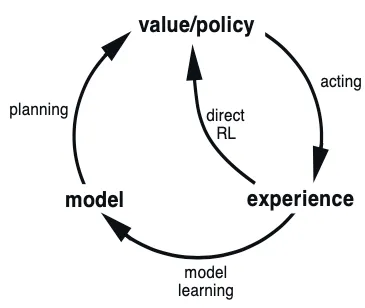
Diagram showing how each component of the RL process fits into a complete algorithm. See Chapter 8 of Sutton & Barto 2nd edition.
There are clearly advantages to both methods. Model-based (indirect) methods can make fuller use of limited data collected (better sample efficiency), allowing for fast learning of more optimal strategies. The models, however, can be limited by design and biases. This makes model-free (direct) methods preferable in some scenarios. Later we shall see that advancements in model-based methods are quickly closing the gap wherever there seems to be an advantage in using model-free methods (e.g. Atari). The algorithm structure shown in the figure gives rise to a natural algorithm structure in which is transition between acting, learning a model and planning happens continually. This is the Dyna architecture which is now explored.
Dyna
If you haven’t already seen it, I highly encourage you to watch the AlphaGo documentary which follows the build up and the match between Lee Sedol and AlphaGo. AlphaGo is build upon the principles developed in this article.

Comments are being migrated. Check back soon.