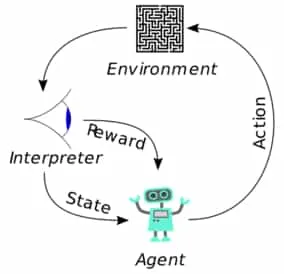
But what is reinforcement learning?
The field of reinforcement learning is at the crossroads between optimal control, animal psychology, artificial intelligence and game theory and has seen a surge of interest with high profile successes such as the dominance of AlphaGo over 18 time world Go champion, Lee Sedol. Reinforcement learning is treated as a subset of machine learning alongside supervised and unsupervised methods. Whereas supervised and unsupervised learning deal with labelled and unlabelled static data respectively, reinforcement learning deals with how an agent should learn to make decisions in an abstract environment with a potentially changing landscape.
History
Reinforcement learning is, for the most part, a formalisation of the notion of trial-and-error learning. At each time-step an agent in an environment with a well defined state can perform some action. This action triggers a response from the environment. The environment rewards the agent for taking this action and moves the agent to a new state. Naturally, the goal of the agent is to maximise the expected reward over time. Further complexity arises in that the agent does not explicitly know how the environment will react and may only have partial information about what state it is currently in. For example, a human playing Montezuma’s Revenge can only see a portion of the environment and cannot be sure about what exact state the surrounding environment is in. It must attempt to make optimal decisions with imperfect information.
Algorithms
Reinforcement learning algorithms are usually categorised as falling into one of two categories - model-free reinforcement learning (MFRL) or model-based reinforcement learning (MBRL). In MFRL an agent directly learns a value function or policy for interacting in the environment by observing rewards and state transitions, while in MBRL the agent uses its interactions with the environment to learn about the environment’s dynamics and thereby model it. Model-free methods have enjoyed success in areas such as robotics and computer games, however they are plagued by high sample inefficiencies. These sample inefficiencies often limit the application of these methods to simulated environments which are less complex than real world dynamics. Learning a model of the environment allows an agent to significantly reduce the dimensionality and complexity of the agent it interacts with, allowing for much improved sample efficiency and performance in many simulated and real world scenarios. By learning a model of the environment, an agent can apply well known supervised learning techniques to plan an optimal strategy for maximising reward. Learning a good model of the environment is a non-trivial task as modelling errors can prove crippling to many tasks. This is the problem of model-bias.
This series of articles starts by discussing the the theory of mind and reinforcement learning that will be used to develop the theory we discuss later. We then discuss popular model-free reinforcement learning methods, especially those that make use of deep neural networks. From this we develop the theory of model-based reinforcement learning and develop critical notions of planning and learning. We then explore state-of-the-art methods which make use of latent representations, prediction, planning and learning with a model. Finally some simple simulations which make use of some of these techniques will be implemented and discussed in detail.

Comments are being migrated. Check back soon.