Hello! Today we’ll be discussing the mathematics of predictive processing - a modern theory for how much of the processing of information is done in the brain. This is also an active area of research with an impact on research in many fields including reinforcement learning. Feel free to follow along with the video presentation embedded below.
Introduction
- Predictive Coding
- Perception
- Let’s use some mathematics (since we’re in this dept)
- Let’s approximate
- Neural implementation
- Hebbian learning
- Free Energy
- Discussion
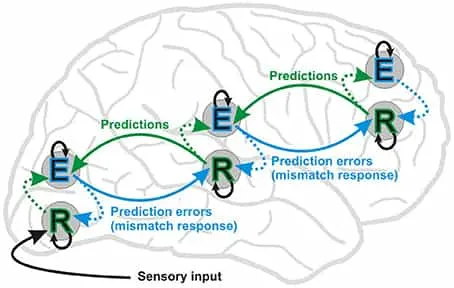
All neural processes consists of two streams: bottom-up stream of sense data, and a top-down stream of predictions. Minimize surprise/free energy- the error between prediction and sense data… To produce/update an effective (but `simple’!) model of our world.
Biological Constraints:
- Local computation - neuron only performs computation on the basis of activity of inputs and associated weights
- Local plasticity - synaptic plasticity only based on activity of pre-synaptic and post-synaptic neurons
A motivated example
Let’s talk through an example. Consider the problem of inferring the value of a single variable from a single observation. For example, a simple organism trying to estimate food size from observed light intensity.
- Let be the food size
- Let be a non-linear function relating size to light intensity
- Then is a noisy estimate of the light intensity s.t.
How could our animal ‘compute’ the expected food size explicitly? Why is this a problem?
Posterior distribution might not take a ‘standard’ form - we would not be able to use basic summary statistics to describe the distribution. How would we compute that integral? Nontrivial. And so comes the physicists best friend - approximation!
The approximate solution!
We now find the most likely size, denoted , that maximises instead of finding the whole posterior distribution. The posterior density is thus . Here but does not depend on We want to find to maximise the posterior. We do this by maximising Update proportionally to
Neural implementation and learning
Notice and are prediction errors. Assume are encoded in strength of synaptic connection. encoded in activity of neurons. Prediction errors can be computed with dynamics: This holds by considering and
Least surprise most expected. Want to maximise . Recall this was not feasible. Simpler to maximise . Even simpler to maximise .
Free Energy
We want approximate distribution, , to be as close as possible to the posterior, , as possible. Kullback-Leibler divergence measures the dissimilarity.
is the free energy. where is independent of Maximising F gives the desired result. i.e. Minimising -F.
I hope you now have some understanding of the intuition behind free energy in the context of prediction. Join in the discussion by commenting below!

Comments are being migrated. Check back soon.