This is the long-form companion to Paper 1 (SAB 2026 submission), about an active-inference agent that has to keep itself alive in a small four-need gridworld under finite perceptual bandwidth. The headline finding is short: replacing uniform observation precision with a need-aligned, fixed-budget selector — what we call κ-attention — more than doubles learning-phase survival; reversing the direction of the selector falls below uniform. The point of the post is to do three things the 12-page paper cannot: (i) say the mechanism in plain English with side-by-side animations, (ii) be candid about where the result is strong and where it leaves genuine uncertainty, and (iii) provide an interactive demo that lets you turn the relevant knobs yourself.
The problem in one paragraph
Any embodied system regulating competing physiological needs runs on a finite perceptual budget. Sharpening any one channel — say, the report from your gut about how hungry you are — costs energy, and the total budget is bounded. Behaviour therefore depends not only on which actions are available but on which channels of evidence are sharpened first. Behavioural ecology has known this for decades (McNamara & Houston, 1986); biological neural systems implement perceptual selection through gain modulation (Bastos et al., 2012). The question here is whether, inside an active-inference agent, reallocating a fixed observation-precision budget toward whichever channel the agent’s own posterior flags as most needed is sufficient as a homeostatic-prioritisation mechanism. Where in the agent’s processing chain that signal enters turns out to matter as much as whether it is present at all.
AffectWorld in 90 seconds
The environment is a 6×6 gridworld with two food and two water tiles per layout. The agent has three active bodily needs — hunger, thirst, and suffocation — each tied to a world resource and to a noisy interoceptive channel, plus one fourth inert control channel that carries no need signal. Hunger and thirst decay by one unit per step and are lethal at zero; suffocation depletes only on water tiles, recovers elsewhere, and is not lethal on its own. Episodes run up to 60 steps and terminate early on death.
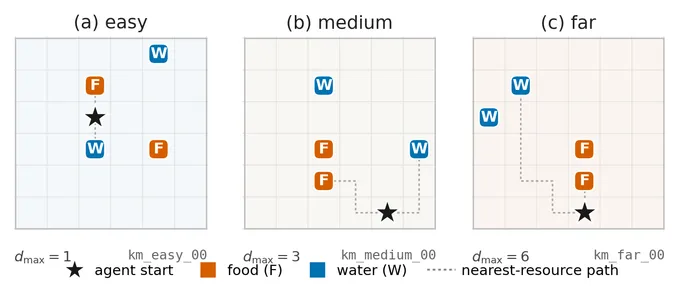
Twelve layouts across easy, medium, and far tiers. The headline results pool eleven of them (L01 is treated as a separate stress-test in the appendix).
The agent itself is an active-inference POMDP solver: it maintains beliefs over body and world states, plans by minimising expected free energy over a horizon of three steps, and updates its observation likelihood online via Dirichlet pseudo-counts. The single architectural intervention is how precision is split across the four interoceptive channels.
Precision as a scalar budget
Each interoceptive channel reports a noisy categorical observation of the underlying body-state level . The likelihood is parameterised by a single scalar — the probability that the per-step observation equals the true level on channel :
A precision of means the agent perfectly observes that channel; means it reads a uniformly random level. The constraint is a fixed soft budget across channels:
Two operating points fall out of this. Uniform allocation gives every channel — every channel reports correctly 65% of the time. Selective allocation gives one attended channel and the other three — one channel is now 90% reliable, the other three are 57% reliable, and the total is preserved. The same K, the same observation channels — only the split changes.
The selector itself is just an arg-max: each step, the agent picks the channel for which its own posterior indicates the largest unmet need ( on the three active channels, zero on the inert one), and reallocates the budget toward it. There is no ground-truth oracle; the selector reads only what the agent itself currently believes.
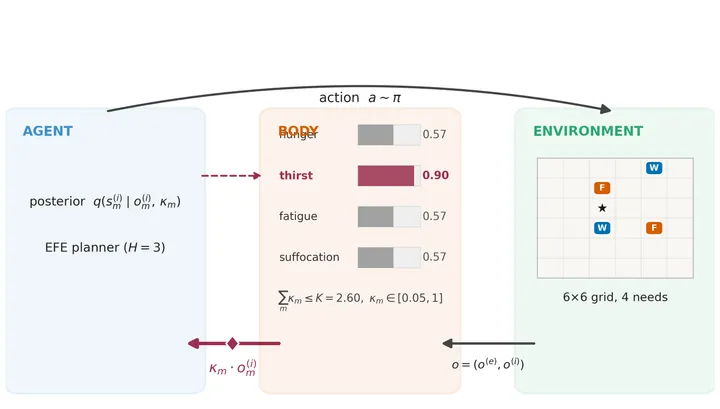
The intervention is small: a single precision-shaped likelihood matrix is read by two downstream consumers — the per-step belief update and the EFE planner. Everything else is held constant across agents.
Try it: three agents, same body, different κ-split
The demo below has three tabs. Mechanism rollout runs three agents side-by-side and lets each one pick from 11 selector mechanisms (need-aligned default, hysteresis, explorative, action-aware, anti-aligned, oracle, random, uniform, and three fixed-channel variants). For each agent you see, in real time: the true body state (coloured bar fill), the agent’s belief about each channel (the thin horizontal line inside each bar — the lag between line and fill is the entire mechanism story made visible), the κ allocation, a rolling 30-step trace of the attended channel, and per-channel Dirichlet sparklines showing how the posterior diagonal mass on each interoceptive likelihood matrix concentrates over time. The Parameter explorer tab shows the real κ × α₀ grid from the paper (toggle between survival rate and cumulative need per step). The Real outcomes tab shows the real per-channel mean-Δ in posterior diagonal mass across 24 paired clusters and the convergence fractions across 352 clusters.
All three agents share an identical body, the same noisy categorical observations, and
the same fixed precision budget K. They differ only in their selector — the rule that decides where the budget is allocated each step. The thin horizontal
line inside each bar shows the agent's belief about that channel; the coloured
fill is the channel's true level. The trace strip below each agent shows the
attended channel for the last 30 steps. The rollout is a stylised body-and-selector
simulator: it shares the paper's depletion, noisy-categorical observation, and
belief-driven selection logic, but does not run the full expected-free-energy planner —
the parameter-explorer tab below shows the real grid from the paper.
Trial-level mean Δ in posterior diagonal mass
Per-channel cluster-bootstrap means with 95% CIs from per_channel_delta_ci.json (24 paired clusters; layout × seed).
Δ is the change over a trial in the agent's Dirichlet posterior diagonal mass
on each channel — exactly what the live sparklines on the rollout tab estimate
from the stylised simulator. Bars are mean Δ; thin brackets are the 95% CI.
Convergence: fraction of trials crossing 50% diagonal mass
From convergence_time.json (352 paired clusters across the full
n=32 broad panel). Threshold = 0.50; window = 5 trials. Higher fraction is
better — it means the per-channel A learning is reliably crossing the
"meaningfully concentrated" line. Median crossing-trial is 5 across all
agents, so the relevant signal is the fraction that reach it at all.
Per-step real-trial replay would need the trial-curve CSVs from runs/actinf_learning_gpu/test_c_plus_v2_kmp_fix/, which live on the
HPC and aren't shipped with the snapshot to keep it under size limits. The Dirichlet
story is faithfully reproducible from the simulator on the rollout tab; the aggregate
numbers above are the real measurements those simulated trajectories are estimating.
Real grid from kappa_alpha_grid.json in the paper repo — pooled across 3
easy-tier layouts × 8 seeds per cell. The two axes: κatt, the precision the
selector concentrates on the attended channel; α0, the Dirichlet prior on
the body-state observation likelihood (lower → looser, higher → more rigid). The
paper's canonical operating point is κatt = 0.90, α0 = 0.1. The
benefit grows fastest as κatt climbs above the uniform allocation
K/4 ≈ 0.65 and as the prior tightens.
A few things to watch for. With the default settings, κ-attention will keep all three active bars away from zero for most of the run, switching the attended channel as need shifts; the Dirichlet sparkline of the attended channel climbs visibly faster than the others. The uniform agent typically dies a little earlier — it never gets a clear read on any one channel and acts on noisy beliefs. The anti-aligned agent dies fastest: it spends its high-precision budget on the channel that needs attention least, and the sparkline shows the wrong channel concentrating fastest while hunger and thirst stay near uniform.
What’s real and what’s stylised. The mechanism rollout is a stylised body-and-selector simulator: it shares the paper’s depletion, noisy-categorical observation, fixed-budget allocation, belief-driven selection, and the κ-weighted Dirichlet update, but it does not run the full expected-free-energy planner. The Dirichlet sparklines you see are the real mechanism applied to the stylised body — the same per-observation acceleration the paper measures, just from a simpler body. The parameter explorer and real outcomes tabs are the real paper data, baked in from
kappa_alpha_grid.json,per_channel_delta_ci.json, andconvergence_time.json. Per-step real-trial replay would need the trial-curve CSVs from the HPC; those aren’t shipped with the snapshot to keep it under size limits.
The headline number
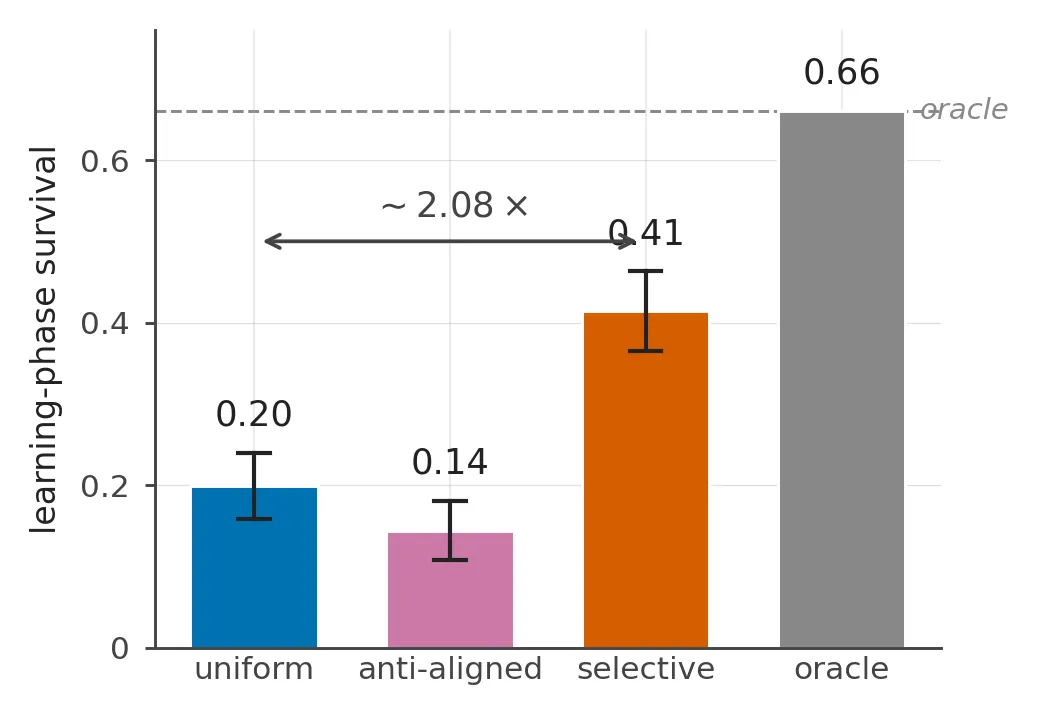
Across 11 layouts and 32 batched seeds per cell, learning-phase survival is:
| Agent | Survival rate | 95% CI | p vs uniform |
|---|---|---|---|
| Uniform | 0.199 | [0.158, 0.240] | — |
| κ-attention | 0.414 | [0.365, 0.463] | ≤ 10⁻⁴ |
| Anti-aligned | 0.144 | [0.108, 0.181] | 0.004 |
Selective allocation more than doubles survival at the same total budget — ≈ 2.08×. The anti-aligned control performs significantly worse than uniform: non-uniform allocation alone is not enough; the direction has to match the agent’s belief about where the need is.
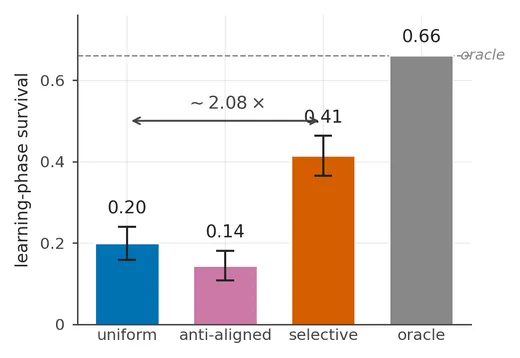
Headline gain. The dashed line is a Gumbel-AlphaZero oracle given the true environment transition function — about 0.66 survival on this benchmark.
The task is hard in this setting: even oracle-dynamics planners reach only about 0.66 survival.
Where the signal does its work
The same shaped likelihood is read by two parts of the agent: the per-step belief update (does the agent know it is hungry?) and the EFE planner (does the agent plan a route to food?). The natural question is whether one of these sites carries most of the benefit.
We test this with an inference-only variant that presents the planner with an unshaped likelihood — selective precision still enters the belief update, but the planner sees uniform K/4 across all channels. If the agent’s beliefs alone were doing the work, this should not hurt. It does:
- At the default prior concentration (), the inference-only variant loses about 20 pp relative to the full κ-attention agent.
- Pooled across six prior concentrations , the loss is 47 pp.
- At rigid priors (), the loss reaches 88 pp — the inference-only agent collapses to the level of the anti-aligned control.
The mirror ablation — keep the planner’s shaped likelihood, disable the inference-stage shaping — actually matches or exceeds the full agent at loose priors. Read together, the dominant pathway is the planner: the inference-stage shaping is at most neutral when the prior is loose, and only becomes load-bearing when the prior is rigid enough that the planner needs help overriding it.
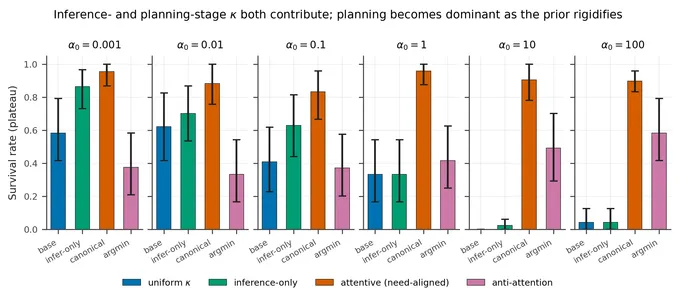
Propagation matters. Suppressing the planner’s access to the shaped likelihood costs about half the benefit at the default prior, growing to almost all of it as the prior tightens.
This is the finding the paper’s reviewers pushed hardest on. The original framing — “the mechanism localises in inference, planning-stage reapplication adds nothing” — turned out to be backwards. The honest read is that the planner-stage shaping carries the gain, with inference-stage shaping serving as insurance against rigid priors.
Direction is essential
A natural worry: maybe any non-uniform allocation helps, simply by perturbing the agent’s beliefs out of a degenerate uniform-precision regime? The direction test answers this cleanly.
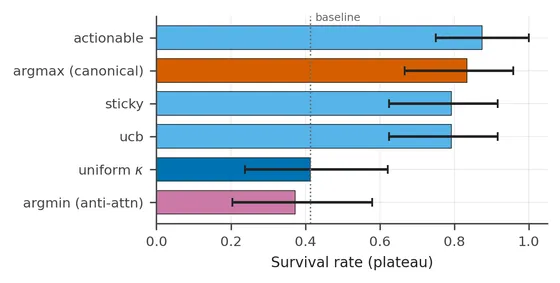
Four need-aligned selector rules (default, action-aware, hysteresis, explorative) plus an oracle ceiling all beat baseline. Only the direction-reversed rule fails.
Sweeping at fixed K confirms it: the need-aligned rule climbs monotonically with asymmetry, reaching a +44 pp gap over uniform at the default . The anti-aligned rule stays flat near 0.36 across the whole sweep. Both converge to uniform at — the uniform allocation — and diverge thereafter. The asymmetry does work because of its direction, not despite it.
A per-observation signature
The attended channel does not only support better action selection in the moment — it also learns its own dynamics faster, per observation, than channels left at uniform precision. Plotted against cumulative observation count (rather than trial index, which mixes in the agent’s survival), κ-attention’s hunger likelihood sits about 0.30 above uniform at every matched data volume. The anti-aligned agent sits about 0.22 above uniform; κ-attention beats the anti-aligned variant by a further ≈ 0.10.
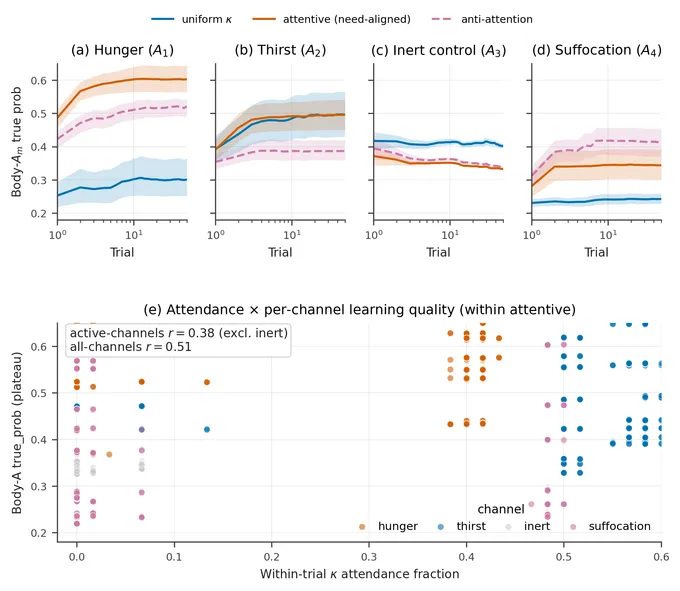
Relevant learning. The attended channel’s Dirichlet posterior concentrates faster than the unattended ones, at matched observation count. This is a per-observation effect, not a survival-mediated one.
This matters because it is a falsifiable mechanistic prediction. Preference-reweighting alternatives — agents that route attention by changing which channel the planner optimises for, rather than by sharpening the likelihood — should not reproduce per-observation Dirichlet acceleration of this shape. A matched-selector dynamic-C comparator is the natural follow-up experiment, and is in the queue for the next paper.
Robustness, briefly
The advantage holds across the three parameters that most plausibly drive performance.
- Prior concentration : κ-attention maintains around 0.85 plateau survival across the range. Uniform collapses at .
- Attended-channel precision at fixed K: monotone, saturating around .
- Budget : κ-attention beats uniform by 32–56 pp at every tested K. Both peak near the canonical ; uniform declines sharply at high K (the planner’s policy-posterior collapses to a single greedy policy), while κ-attention preserves cross-channel asymmetry and avoids overcommitment.
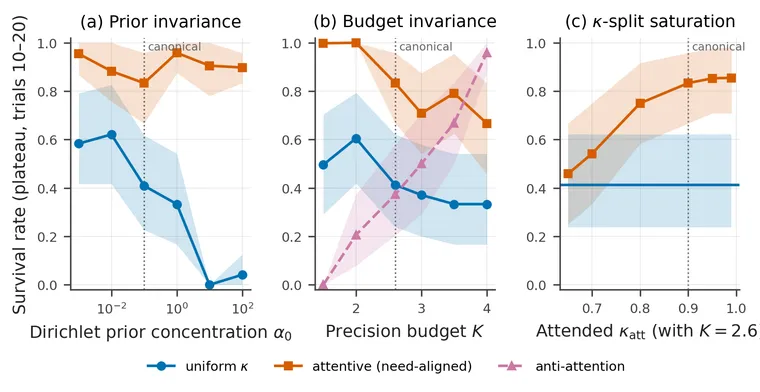
Three orthogonal robustness slices. The gain is not the artefact of a particular operating point.
The non-stationarity sweep tells a similar story: the advantage holds in sign across tile-mutation rates of 0.02–0.10, though the magnitude collapses alongside absolute survival at the higher rates.
What this paper does not settle
A few things worth saying without the page-budget pressure of LNCS.
The result is selector-fixed, not actuation-site-identified. All experiments share a single need-aligned selector and vary where it routes. The claim is therefore that selective interoceptive precision is one sufficient implementation of homeostatic prioritisation, not that it is the only one. A matched-selector preference-reweighting comparator is the natural next experiment — and is the planned follow-up paper.
The K = 4 budget regime is a special case. At , the soft-budget cap binds ( clips to 1, leaving residual budget unused), so the direction-of-asymmetry claim is cleanly identified only at the canonical where no channel saturates. The K = 4 crossover is a regime where the test loses identifying power, not where the mechanism reverses.
The anti-aligned-vs-baseline contrast is the weakest test. The κ-attention-vs-baseline result passes at with comfortable margin; the anti-aligned-vs-baseline result () clears only narrowly and warrants higher-N replication. The qualitative claim — anti-aligned falls below uniform — is robust across selector variants and parameter sweeps, but the specific point estimate should be read with that caveat.
The κ router is hand-specified. Whether a learned router converges to the same need-aligned policy is the obvious follow-up. There is no theoretical reason it should not — the need-belief signal is in the agent’s posterior, freely available to any parametric router — but it is not what this paper tests.
Biology
The κ-allocation maps cleanly onto dynamic gain modulation of interoceptive cortex (Seth & Friston, 2016; Fermin et al., 2022), where interoceptive prediction errors gate cortical responsiveness in proportion to metabolic urgency. The cleanest biological correlate is the AgRP-neuron literature (Livneh et al., 2017): AgRP activity gates cue–resource association in rodent insular cortex on a timescale of 1–2 seconds, and the per-observation Dirichlet acceleration of the previous section maps onto exactly that gating window. Disruption of this gating — anterior insular lesion or interoceptive agnosia — predicts impaired homeostatic prioritisation, most severely during the early novel-environment phase where the κ-attention vs uniform gap is largest in this paper.
The prediction is sharp enough to be testable: per-observation interoceptive learning rates should be highest on the currently-most-needed channel, and that asymmetry should disappear under conditions that disrupt insular gating.
Reproducibility
Code, layout banks, configs, and analysis pipelines are at the anonymised snapshot
anonymous.4open.science/r/attention-aif-sab2026-snapshot-C0E3
during review; the canonical (de-anonymised) repo will go live on acceptance. The
snapshot is built from a single source commit via an idempotent leak-scanned manifest;
the audit log of every build sits alongside it in the source repo. The full paper PDF
and supplementary material are linked from the publications page.
A one-command smoke test reproduces a single-layout headline contrast in under ten minutes on a single GPU; the full 11-layout × 32-seed panel takes about three hours on the same hardware. The HPC sweep scripts are included.
What comes next
Three immediate follow-ups, in priority order:
- Matched-selector dynamic-C comparator. The cleanest test of the per-observation Dirichlet acceleration prediction. A properly-powered version of this experiment is the planned next paper, aimed at IWAI 2026 or AAAI 2027 depending on timing.
- Learned κ router. Replace the hand-specified arg-max selector with a small parametric router and ask whether it converges to need-alignment from the gradient signal alone.
- Forced-multi-need tier. The dynamic-vs-fixed-channel gap is largest in regimes where which channel dominates changes within a trial. The existing layout bank has only modest dominance shifts; a targeted layout tier where food and water pressure alternate within an episode would isolate the dynamic-selection benefit sharply.
If the matched-selector comparator falsifies the per-observation prediction — i.e. preference-reweighting reproduces the Dirichlet acceleration — the paper’s positioning reframes substantially but the headline survival result stands. Either outcome is publishable; the framing is what the next paper does.
The paper
Interoceptive Attention as Dynamic Homeostatic Prioritization in a Foraging Agent. Grimbly, S. J. (2026). Submitted to SAB 2026 (Simulation of Adaptive Behaviour; Springer LNCS). Preprint and code at the anonymised snapshot.
Comments, corrections, and reproduction attempts welcome at askingwhy@stjohngrimbly.com.

Comments are being migrated. Check back soon.